


英特尔在7月下旬的英特尔加速大会上宣布了其未来半导体工艺节点的新名称,受到了很多批评。新节点名为英特尔7、4、3和20A。业内专家批评英特尔将其10nm增强型superin工艺节点称为“英特尔7”。(就在上周的英特尔创新开发者大会上,英特尔宣布并展示了使用英特尔7工艺节点的第12代i5、i7和i9酷睿处理器,因此这种工艺技术显然是掌握得很好的。)该公司现在使用“Intel 4”来命名之前被称为7nm的节点。Intel 3和Intel 20A是全新的节点名称。这种节点重命名部分源于市场营销,部分只是面对现实。
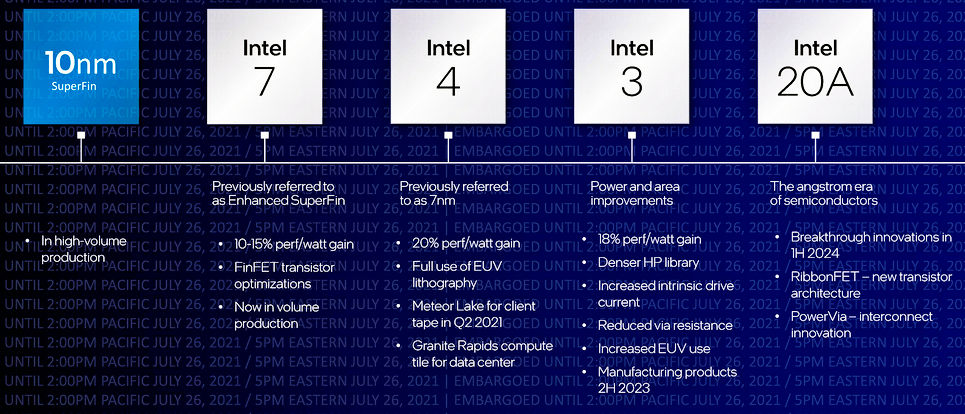
英特尔重新命名了即将推出的工艺节点,以符合行业惯例,而不是自己对现实的看法
过去,英特尔曾表示,其10nm增强型superin节点(现在更名为英特尔7)在功率和性能上与台积电的7nm节点大致相当。混乱的,不是吗?该公司还表示,行业分析师已经要求英特尔更新其工艺节点命名,以反映该公司在半导体工艺领域的真实竞争地位。所有这些都是重命名节点的营销部分。
现实的部分是:纳米命名法在很长很长一段时间内都不准确。不是对英特尔,当然也不是对任何其他晶圆代工厂。这种情况就像热门喜剧《到底是谁的台词》中的评分系统一样。分数不重要。
几年前,进程节点的命名是基于晶体管的最小特征尺寸。这种命名惯例是专门为平面MOS晶体管开发的,最小的晶体管特征总是晶体管的栅极长度。当finfet取代平面MOS晶体管时,这种命名惯例就被抛在了窗外,所有供应商的进程节点名称都变成了你从等效的平面MOS晶体管获得的功率和速度的估计等价物。只不过他们不能再制造平面MOS晶体管了。平面晶体管技术已经过时。在目前的光刻技术水平下,MOS晶体管还不能很好地工作。这就是我们转向finfet的原因。早在2011年,英特尔就在22nm节点上推出了其首个FinFET工艺。
带场效应管和埃
十年后,晶体管的基本结构将再次发生变化。
FinFET门由三面驱动。这比平面MOS晶体管的驱动多了两个面,这使得晶体管性能更好,但代价是更复杂的制造技术。然而,驱动三面FinFET晶体管的栅极不再达到所需的速度和泄漏电流。现在我们必须从大门的四面进攻。这些四边门驱动结构通常被称为“四周门”或GAA。
通用,除了英特尔,该公司称其GAA晶体管为“ribbonfet”,目前计划出现在英特尔20A工艺中,该工艺将于2024年上半年出现(除非延迟)。注意进程名中的“A”。" A "代表"埃"与之前的工艺节点不同,英特尔将这个工艺节点称为“Intel 2”,而是将单位从纳米转换为埃。1埃等于10-10M,或者十分之一纳米。我认为我们应该简单地忽略一个事实,即英特尔从更大的工艺节点中去掉了“nm”。
据推测,这种命名法的变化允许分数纳米节点命名。这和我们之前用微米的情况很相似。在黑暗时代,我们有3、2.5、2、1.5、1.3、1.2,然后是1微米的工艺步骤,接着是0.8、0.75、0.7、0.5,一直到0.25微米左右。就在那时,我们从微米跳到纳米。根据我最好的回忆,命名法的变化发生在0.18微米,也就是通常所说的180纳米。那是什么时候?1998左右。二十多年前。
这意味着当埃时代开始时,纳米工艺节点尺将被使用近四分之一个世纪。因特尔埃命名法允许该公司将进程节点命名为因特尔18A、因特尔17A、因特尔16A等等。这听起来比Intel 1.8、Intel 1.7、Intel 1.6等等好太多了,不是吗?听起来他们这样做更有进展,对吧?然而,从一个节点到下一个节点的进度几乎没有以前那么大了。从上图中,您可以看到从一个英特尔工艺节点到下一个节点,性能/瓦特的提高在10%到20%之间,而该图像甚至没有讨论密度的提高。
摩尔定律在坟墓里奄奄一息
这就引出了本文的核心问题。根据上面所写的,我有一个非常悲伤的消息要告诉你。尽管英特尔首席执行官帕特·盖尔辛格在上周的英特尔创新大会上大胆而热情地承诺,在未来10年里,每年都要达到或打破摩尔定律,但摩尔定律已经死了。通过从一代到下一代削去几埃来缩放一个过程节点并不能实现晶体管密度的翻倍,这是摩尔定律的真正本质。
在我看来,围绕摩尔定律有很多困惑。首先,摩尔定律长期以来一直与登纳德比例(Dennard Scaling)过于紧密地交织在一起,登纳德比例是指平面MOSFET的速度和功率随着晶体管密度的增加成比例地下降。在半导体的早期,当一种新的工艺技术将晶体管的面积缩小50%时,晶体管的速度将翻倍,功率将减半。每隔几年,我们就有一半大小的晶体管,速度是原来的两倍,功率是原来的一半。那的确是一段非常美好的时光,摩尔定律也正处于鼎盛时期。然而,Dennard Scaling是一个专门针对平面MOS晶体管的观察,我们已经有大约十年没有使用最先进的新工艺节点来制造这种晶体管了。
摩尔定律并不是指晶体管的功率或速度。摩尔定律指出,芯片上的晶体管数量大约每两年翻一番。这就是它的全部内容。如果你愿意,你可以查一下。1965年4月19日,戈登·摩尔在《电子》杂志上发表的原创文章题为“把更多的元件塞进集成电路它被贴在英特尔的网站上供你阅读。这篇文章发表于摩尔和鲍勃·诺伊斯创立英特尔的三年前,当时摩尔和诺伊斯都还在仙童半导体公司工作。
摩尔在他开创性的文章中做出了令人难以置信的预言。半导体行业最终接受了他的预测,并将其转化为一个自我实现的预言,这是基于非常少的数据点。第一个数据点是一个晶体管。第二个数据点是第一个商用集成电路,一个3输入NOR门,称为仙童μLogic Type G RTL芯片。
根据大卫·帕特森博士的说法,摩尔定律一直持续到2015年,直到它耗尽了汽油。(参见“五十年(或六十年)的处理器开发……为了这个?)帕特森怎么能说摩尔定律在2015年就死了,而英特尔的高管们却一致地让你相信摩尔定律在今天依然有效?这是因为摩尔1965年论文第二页的一句话。那句话是:“……在一个电路上产生越来越大的电路功能。单半导体衬底(重点是我的。)摩尔定律是关于单片集成电路的,而这并不是半导体行业的发展方向。
事实上,在50th2003年,在一场题为“没有指数是永远的戈登·摩尔自己也明确地说过:“……没有任何物理量可以永远以指数方式变化。”摩尔定律早在20年前就已经消亡了,而摩尔自己也看到了这一点。
我目前认为摩尔定律终结的典型代表是英特尔(Intel)自己的庞特维奇奥(Ponte Vecchio) GPU。英特尔正在使用47个有源“瓦片”(英特尔对多芯片封装中的芯片或芯片的名称)组装这一集成设备,这些“瓦片”由多个半导体供应商从五个不同的半导体工艺节点制造,所有这些都使用2.5D和3D组装技术组合在一个封装中,生产出具有超过1000亿个晶体管的集成产品。(请务必用卡尔·萨根(Carl Sagan)的口音阅读最后一句话,并强调“十亿”。)
一些人声称摩尔在他的文章中预见了多芯片封装。他们引用了这句话:
“事实可能证明,用较小的功能构建大型系统更经济……”
但他们似乎忽略了这句话的后半部分:
“……它们是分开包装并相互连接的。”
这里,Moore显然是在讨论在一块电路板上使用多个单独封装的芯片,这是自集成电路于20世纪60年代首次出现以来电路板级设计的主要内容。从我的角度来看,摩尔显然没有用这句话预测到今天的多芯片封装。事实上,他的文章讨论了每个IC有65,000个组件的单片IC在10年内出现的可能性,到1975年,这远远超过了1965年Moore文章发表时任何单个印刷电路板所能容纳的离散组件。谁可能需要超过65,000个组件呢?如果摩尔在当时就考虑过这个问题(他可能确实考虑过),他一定已经看到,多芯片封装技术在遥远的未来才会被需要。好吧,这样的未来已经到来。

英特尔的庞特维奇奥GPU集成了来自5个不同处理节点的47块瓷砖,将1000亿个晶体管塞进一个封装中。(图片来源:英特尔)
多芯片封装之所以有意义,只是因为不同的工艺节点提供了不同的成本/性能/能力权衡,因为我们处于当前芯片制造设备的十字线极限,因为2.5D和3D封装技术现在已经足够实用和经济,可以使这种方法在商业上工作。假设你拥有可靠而经济地组装所有这些芯片或芯片所需的制造工艺,为什么不应该用最高效的半导体工艺节点来制造块和子系统呢?维奇奥桥无可否认是一个工程奇迹,但它绝对不是一个单片芯片,所以它不是摩尔定律的原始例子。
除了摩尔定律的巨大神话基础,对我们大多数人来说,英特尔如何将1000亿个晶体管塞进维奇奥桥的封装中并不重要。对于在设计中使用维奇奥桥图形处理器的系统工程师来说,这并不重要。对于使用使用庞特维奇奥图形处理器的图形软件或电脑游戏的人来说,这并不重要。设备的性能、功率和价格(所有工程设计的三个基本“P”)对我们这些生活在包装之外的人来说很重要。
英特尔(Intel)计划以类似的方式生产Sapphire Rapids,这是该公司下一代至强(Xeon)处理器的代号。英特尔将使用四个CPU芯片和基于EMIB(嵌入式多模互连桥)技术的2.5D组件来制造Sapphire Rapids。Sapphire Rapids处理器的版本还将在同一个封装中包含多个HBM2(高带宽内存2)DRAM堆栈。

英特尔的Sapphire Rapids,下一代至强CPU,将包含四个CPU瓦,由四个EMIB桥连接。(图片来源:英特尔)
多芯片封装并非英特尔独有。远非如此。AMD、Nvidia和Xilinx都生产表面看起来像单片集成电路的集成设备,但内部是多芯片设备——相互连接的瓷砖或芯片集合。(实际上,这些无晶圆厂半导体供应商的设备都是由3制造和封装的理查德·道金斯-一方代工厂——通常是台积电。)这种情况已经持续了十多年。
例如,Xilinx在2011年推出了Virtex-7 2000T FPGA。它基于一个多芯片封装,将四个FPGA芯片放在一个硅中间层上。TSMC为Xilinx制造该设备。大约在同一时间,多芯片封装允许Xilinx在可能将这些收发器直接构建到CMOS FPGA芯片之前,将28 Gbps收发器集成到其Virtex-7 580T FPGA中。Xilinx在每一代新的FPGA中都扩展了多芯片封装的使用。这是一个很好的迹象,表明多芯片封装工作良好,至少在高端IC市场。
欢迎来到埃时代。这是一个“超越摩尔”的时代。现在,从情感上和经济上都不需要把所有东西都放在一个芯片上,这个半导体制造的新时代已经生产出比以往任何时候都更大、更好的集成器件。仅仅依靠单片集成电路和摩尔定律是无法实现这些好处的。
摩尔定律可能已死,但摩尔定律的精神却永存。问问帕特·盖尔辛格就知道了。
有关摩尔定律起源的更多精彩细节,请参见“摩尔定律和七种设备”。



两个评论:
回复:“该公司还表示,行业分析师已经要求英特尔更新其工艺节点命名,以反映该公司在半导体工艺领域的真实竞争地位。”
其中一位分析师是EE Journal://www.morningcaffee.com/article/no-more-nanometers/
回复:“摩尔定律说芯片上的晶体管数量大约每两年翻一番。它就是这么说的。”
1965年的一篇文章“填鸭式增加组件……”实际上说它每年会翻一番。“最低组件成本的复杂性以每年大约两倍的速度增长……当然,在短期内,这一速度如果没有增加,也可以预计会继续下去。”在
从长期来看,增长速度有点不确定,尽管没有理由相信它在至少10年内不会保持几乎不变。”
10年后,也就是1975年,摩尔将他的预测修正为每两年翻一番。那也是卡弗·米德开始宣传“摩尔定律”这一预言的时间。
这是另一个“看,妈妈,我能做什么!”而不是我应该做什么。
认为仅仅是人类就能想出使用这么多晶体管的设计是荒谬的。
或者说,在如此大规模的情况下,设计定时关闭和验证是可能的。
或者可怜的HDL工具可以开始处理这么多的门。
或者有可能以必要的速度在芯片上或从芯片上获得足够的数据。
或者有可能定义这么多门的互连。
摩尔定律是否存在是无声的,因为芯片严重短缺。
现在是时候采用一种新的设计入口方法和一种适用于异构设计的方法了。
有人听说过M1芯片吗?