根据希腊神话,奇美拉(又名奇美拉)是一种巨大的喷火杂交生物,由不同的动物部分组成。如今,“奇美拉”这个词已经用来描述(a)任何神话或虚构的生物,它们的部分取自各种动物,(b)任何由非常不同的部分组成的东西,或者(c)任何被认为是充满想象力的、令人难以置信的或令人眼花缭乱的东西。
后一种意思适用于我们这里因为我刚刚被介绍过嵌合体GPNPU(通用神经处理器单元)从聪明的小伙子和小伙子在二次曲面,这个小流氓确实按下了我“疯狂想象”和“令人眼花缭乱”的按钮。
Quadric公司成立于2017年,最初计划基于他们新颖的Chimera GPNPU架构提供推理边缘硅(即,针对物联网“边缘”应用程序的推理芯片,这是互联网与现实世界相遇的地方)。他们的第一块硅片很快就得到了验证,一些早期用户已经开始试用了。然而,最近,在Quadric公司那些身披权威和权力走廊的人决定将Chimera GPNPU授权为IP,可以整合到其他公司的片上系统(SoC)设计中,因为这将使他们的技术暴露给更广泛的客户群。
为了理解Chimera GPNPU为什么如此“想象力丰富”和“令人眼花缭乱”,让我们从下面的图像开始考虑,它提供了面部识别和认证管道的简化视图。

面部识别和认证管道(来源:Quadric)
让我们假设所有这些功能都是在智能相机SoC中实现的。让我们还假设一个摄像头/传感器正在向左边的第一个功能块提供视频流。这是我们可能会在未来几代人身上看到的门铃摄像头例如。
观察两个粉红色的“人脸检测”和“人脸认证”功能,它们是使用人工智能/机器学习(AI/ML)推理实现的。令人惊讶的是,在过去的几年中,这种类型的推理的使用是多么迅速,从学术上的好奇心过渡到早期部署,几乎成为现代软件开发中的一个事实上的元素。
将推理(基于视觉、声音等形式的刺激)作为开发人员用于创建应用程序的构建模块之一的想法,我们可以将其视为“软件2.0”;问题是,这并不像我说的那么简单(如果你大声说话,激烈地打手势,一切都可以听起来很容易)。soc通常应对软件2.0挑战的方式如下(a)所示。

传统智能相机SoC vs.基于Chimera gpnpu的SoC
(来源:二次)
这里需要注意的关键点是,神经处理器单元(NPU)、矢量数字信号处理器(DSP)和实时中央处理单元(CPU)作为三个独立的核心呈现。现在回到我们的面部识别和身份验证管道。使用传统方法,与前两个块(“调整大小”和“通道解包”)相关的处理将在DSP核心上执行。
然后,由DSP核心生成的数据将被转移到运行在NPU核心上的神经网络(NN)“人脸检测”图/模型。npu的输出——一堆潜在的边界框——将被转移到CPU核心,它将运行“非最大抑制(NMS)”算法来决定使用最好的一个。
然后,DSP将使用CPU识别的边界框对图像执行更多任务,例如“裁剪+灰度”和“调整大小”(即在本例中“正常化”)。最后,这些数据将被转移到NPU核心上运行的“面部认证”图/模型。
假设你以这种方式实现东西,却发现你没有得到你想要的帧速率/吞吐量。您如何着手找出性能瓶颈在哪里?另外,在三个核心之间传输数据消耗了多少电力?
这里真正的潜在问题是,拥有三个独立的处理器核心会使整个设计过程变得繁琐。例如,硬件设计人员必须决定每个核心需要分配多少内存,以及功能块之间需要多大的缓冲区。同时,软件开发人员需要决定如何在核心之间划分他们的算法。这是一种痛苦,因为应用程序程序员不希望花大量时间考虑他们所运行的目标平台的硬件细节。
另一个需要考虑的问题是ML模型正在迅速发展。今天,人们正在运行几年前还没人听说过的视觉变形金刚。谁知道未来几年会运行什么样的ML模型呢?
所有这些都是如此可怕的复杂,这是ML部署没有加速的原因之一,因为针对这种常规目标平台进行开发在编程、调试和性能调优等方面是一件非常痛苦的事情。
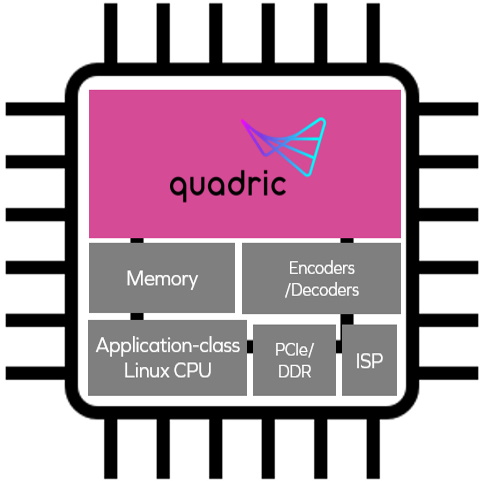
所有这些都将我们带回到gpnpu的Chimera家族,它们由前面插图(b)部分的粉红色区域表示。GPNPU将DSP, CPU和npu的最佳属性组合在一个单核中,作为传统CPU/DSP的组合,可以运行C/ c++代码,具有完整的32位标量+向量指令集架构(ISA),以及可以运行为8位推理优化的ML代码的NN图处理器。这种方法允许开发人员在同一个引擎上运行两种类型的代码,从而唯一地解决了信号链的挑战。
我们可以认为Chimera GPNPU是经典的冯·诺依曼RISC机器和收缩阵列/ 2d -矩阵架构的混合体。从处理器的角度来看,我们有单个64位指令字和单个指令发出/时钟。我们也有标量和向量/矩阵指令无模态地混合从时钟滴答到时钟滴答。
Chimera GPNPU方法的关键优势之一是它能够适应不断发展和日益复杂的ML网络。像变压器这样的东西变得越来越复杂,想要在神经网络的体系结构中做更多的条件控制流,无论是CNN, RNN, DNN等等。传统的npu通常就像硬连接的加速器,不能执行条件执行。例如,如果你有一个专用加速器,你不能在14层的某个地方停下来检查条件或中间结果,然后分支并做各种面向控制流的事情。在这些情况下,你必须在NPU和CPU之间来回传输数据,这将导致性能和功耗的下降。相比之下,使用Chimera GPNPU,你可以逐个时钟地在神经网络和控制代码之间来回切换。
这里还有很多要谈的,比如Chimera GPNPU在执行卷积层方面的出色表现,这是cnn的核心,以及它们的TOPS(每秒万亿次运算)分数,这让我高兴得热泪盈眶。不幸的是,这是一个“有这么多事情要做,但时间太少了”的例子(如果你给Quadric的人打电话,他们会很高兴地告诉你所有的事情)。
我想在这里讨论的最后一个主题是快速概述Quadric软件开发工具包(SDK),如下所示。

Quadric的软件开发工具包(SDK)(来源:Quadric)
归根结底,一切都是由软件驱动的。使用TensorFlow、PyTorch、Caffe等框架生成的训练好的神经网络图/模型被输入到Apache TVM(用于cpu、gpu和ML加速器的开源机器学习编译器框架)中,生成Relay输出(Relay是TVM框架的高级中间表示)。
中继表示的转换和优化由CGC (Chimera Graph Compiler)执行,CGC将转换和优化后的神经网络输出为c++代码。Chimera LLVM c++ Compiler将这些代码与开发人员的c++应用程序代码合并,所有这些输出都是一个可执行文件,运行在目标硅/SoC中的Chimera GPNPU上。
注意,Quadric SDK是作为预先打包的Docker镜像发布的,用户可以下载并在自己的系统上运行。Quadric很快就会把这个SDK托管在Amazon Web Services (AWS)上,这样用户就可以通过自己的网络浏览器访问它。
我特别感兴趣的是,Quadric的人员正在开发图形用户界面(GUI),它可以让开发人员拖放包含CPU/DSP代码和NPU图形/模型的管道构建块,将它们拼接在一起,并将所有内容编译成Chimera GPNPU图像。这种无代码开发方法将使大量开发人员能够为含有Chimera GPNPU的硅创建应用程序。
唷!我对这一切感到非常兴奋。我认为这种技术的应用领域只会受到我们想象力的限制。你说呢?你有什么想法想和我们分享吗?